协同过滤算法一般分为两类:
1、基于记忆的协同过滤:记住每个人消费过的什么东西,然后给他推荐相似的东西,或者推荐相似的人消费的东西。
2、基于模型的协同过滤:从用户物品矩阵中学习一个模型,从而将矩阵的空白处进行填满。
基于用户的协同过滤(user_cf)
思想
先根据历史消费行为帮你找到一群和你口味相近的用户,然后再根据这些和你很相似的用户在消费什么新的、你没有见过的物品,都可以推荐给你。
原理
整个基于用户推荐的核心是用户物品的关系矩阵
-
根据用户的历史购买数据,准备用户向量
-
向量的维度是物品个数
-
向量维度设为 0 和 1,0 代表用户没有购买该物品,1 代表用户购买过该物品
-
-
用每一个用户的向量,两两计算用户之间的相似度,设定一个相似度阈值或设定一个最大数量,为每个用户保留与其最相似的用户
-
为每个用户产生推荐结果
- 把与用户最相似n个用户的物品取出来,去掉用户自己已经购买过的物品,然后计算用户对物品的匹配分数进行排序输出作为推荐结果。
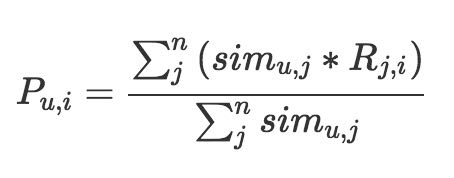
其中等式左边表示用户 u 对物品 i 的匹配分数,等号右边的分母是把和用户 u 相似的 n 个用户的相似度相加,分子是把 n 个用户对物品 i 的态度,按照相似度加权求和。
这里用户对物品的态度可以使用用户对物品的浏览次数、点击次数进行表示,也可以使用用户是否购买过物品表示。
改进
1、惩罚对热门商品的喜欢程度
2、增加喜欢程度的时间衰减
应用场景
基于用户的协同过滤有两个产出:
- 1、相似用户列表
- 2、基于用户的推荐结果
所以我们不但可以推荐物品,还可以推荐用户,比如在一些社交平台上看到:“相似粉丝”就是通过这种方法计算的
基于物品的协同过滤推荐(item_cf)
基于用户推荐算法的问题
1、用户数量往往比较大,计算起来非常吃力;而物品数量往往小于用户数量,所以计算物品的相似度不会成为瓶颈。
2、用户的口味其实变化还是很快的,不是静态的,所以兴趣迁移问题很难反应出来;而物品之间的相似度比较静态,它们变化的速度没有用户的口味变化快;所以可以解决用户兴趣迁移的问题。
3、数据稀疏,用户和用户之间有共同的消费行为实际上是比较少的,而且一般都是一些热门物品,对发现用户的兴趣帮助不大。物品对应的消费者数量较大,对于计算物品之间的相似度稀疏度是好过计算用户之间的相似度的
思想
与基于用户的推荐不同,基于物品的推荐首先计算物品的相似度,然后在根据用户消费过、或者正在消费的物品为其推荐相似的
原理
-
1、构建用户物品的关系矩
-
是一个稀疏向量
-
矩阵的行表示物品、列表示用户
-
向量各个维度的取值是用户对这个物品的消费结果,可以是本身的布尔值,也可以是消费行为量化,如时间长短,次数多少,费用大小等,还可以是消费的评价分数
-
没有消费过的物品为零
-
-
2、两两计算行向量之间的相似度,得到物品相似度矩阵。
- 一般选择余弦相似度,计算公式如下:
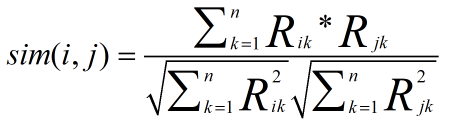
其中分母计算两个物品向量的长度,求元素值的平方和再开方。分子是两个向量的点积,相同位置的元素值相乘再求和。
- 3、产生推荐结果
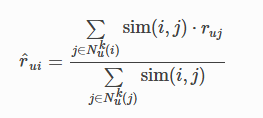
- 要预测用户 u 对物品 i 的分数,遍历用户 u 评分或交互过的所有物品,假如一共有 m 个,每一个物品和待计算物品 i 的相似度乘以用户的评分,这样加权求和后,除以所有这些相似度总和,就得到一个加权平均评分,作为用户 u 对物品 i 的分数预测。这里的用户评分可以用用户对物品的点击次数表示
改进
-
物品中心化:把矩阵的分数,减去的是物品分数的均值;先计算每一个物品收到评分的均值,然后再把物品向量中的分数减去对应物品的均值。主要目的是去掉物品中铁杆粉丝群体的非理性因素
-
用户中心化:把矩阵的分数,减去对应用户分数的均值;先计算每一个用户的评分均值,然后把他打过的所有分数都减去这个均值。主要是因为每个人的标准不一样,有的人标准严苛,有的人标准宽松,所以减去用户的均值可以在一定程度上仅仅保留了偏好,去到主观成分
应用场景
-
TopK推荐,形式上也常常属于类似“猜你喜欢”
-
相关推荐,当用户访问物品的详情页,或者完成对物品购买行为的结果页面时,就可以推荐与物品相似的物品给用户,也就是“看了又看”或者“买了又买”的推荐场景
矩阵分解
近邻模型的不足
-
1、物品之间存在相关性,信息量不会随着向量维度增加而线性增加
-
2、矩阵元素稀疏,计算结果不稳定,增减一个向量维度,会导致近邻结果差异较大
SVD算法
SVD的全称是奇异值分解,属于线性代数的知识;而推荐算法用到的并不是正统的奇异值分解,而是一个伪奇异值分解。
思想
矩阵分解就是将用户物品评分分解为两个小矩阵,一个矩阵代表用户偏好的隐因子向量组成,另一个矩阵代表物品语义主题的隐因子向量组成。这两个矩阵相乘得到的维度和用户物品评分矩阵的维度一样。这两个矩阵的学习方法是套用了机器学习的方法,就是使用优化算法求解损失函数。
原理
-
1、准备好用户物品的评分矩阵,每一条评分数据看做一条训练样本;
-
2、给分解后的 U 矩阵和V矩阵随机初始化参数
-
3、用 U 和 V 计算预测后的分数
-
4、计算预测的分数和实际的分数误差
-
5、按照梯度下降的方向更新 U 和 V 中的元素值;
-
6、重复步骤 3 到 5,直到达到停止条件。
改进
-
增加偏置信息
-
由于用户评分标准不一样,有的高分,有的低分。还有物品收到的评分也是不标准的。所以可以将用户对物品评分的偏置信息抽出来加入 SVD 中
-
一个用户对物品的评分有四部分组成:全局平均分、物品的评分均值、用户的评分均值、用户和物品之间的兴趣偏好
-
-
增加历史行为
-
有的用户评分比较少,事实上相比于沉默的大多数,主动评分的用户还是比较少的,换句话说,显示反馈比隐式反馈少,所以可以在模型增加隐式反馈,另外可以加入用户的个人属性,如性别等,来弥补冷启动的不足。在SVD中结合用户的隐式反馈行为和属性,这套模型叫做 SVD++
-
隐式反馈的加入
- 除了假设评分矩阵中的物品有一个隐因子之外,用户有过行为的物品集合也都有一个隐因子向量,维度是一样的。把用户操作过的物品隐因子向量加起来,用来表达用户的兴趣偏好。
- 用户属性,全都转化为0-1特征后,对每一个特征也假设都存在一个同样维度的隐因子向量,一个用户的所有属性对应的隐因子向量相加,也代表他的一些偏好
-