文本数据
对于用户这一端,产生的文本数据主要有用户注册时填写的信息,用户的评论等,而物品这一端也会产生大量的文本数据,主要包括物品的标题、描述和物品其他文本属性等,我们可以通过这些数据构建物品画像,从而丰富我们的用户画像。
构建用户画像
把所有非结构化的文本结构化,去粗取精,保留关键信息;
结构化文本
我们一般拿到的文本通常是一段话,也就是“非结构化的”,但是计算机在处理时,只能使用结构化的数据索引、检索,然后向量化进行计算。我们可以使用NLP技术对文本进行分析:
- 关键词提取,最基础的标签来源,也为其他文本分析提供基础数据,常用算法有TFIDF和TextRank;
- 实体识别,识别出文本中的人物、地点、著作等专有名词,常用基于词典的方法和CRF模型;
- 内容分类,使用分类模型将文本按照分类体系进行分类,用分类来表达较粗粒度的结构化信息;
- 文本聚类,在没有分类体系的情况下,对文本进行无监督建模,将文本划分为多个类别;
- 主题模型,从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况,如LDA;
- 嵌入,也叫作“embedding”,通过模型挖掘字面意思之下的语义信息,并且用有限的维度表达出来。如word2vec。
用户&物品结构化信息合并
根据用户行为数据把物品的结构化结果传递给用户,与用户的结构化信息进行合并。
- 直接将用户产生过行为的物品标签累加在一起
- 把用户对物品的行为如购买、收藏等,看成一个分类问题。那么物品的标签就相当于特征,而挑选出用户感兴趣的物品标签就可以转化为一个特征选择问题。具体的做法:
- 1、把物品的结构化内容看成文档
- 2、把用户对物品的行为看成类别
- 3、每个用户有交互的物品集合就是一个文本集
- 4、在这个文本集合上使用特征选择算法选出每个用户关心的东西,如卡方检验(CHI)、信息增益(IG)
卡方检验
本质上是检验“某个词和类别C相互独立“这个假设是否成立,如果假设不成立程度越大,那么词与类别C的相关度就越高。
| 卡方检验 | 属于类别C | 不属于类别C | 总计 |
|---|---|---|---|
| 包含词W | A | B | A+B |
| 不包含词W | C | D | C+D |
| 总计 | A+C | B+D | N=A+B+C+D |
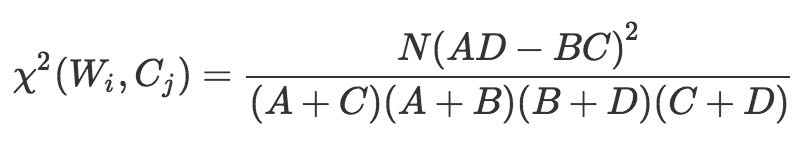
卡方值越大,说明“词和类别相互独立”假设越不成立,也就是说词和类别越相关。
信息增益(IG)
表示得知特征A的信息而使得类Y的信息的不确定性减少的程度
- 1、统计全局文本的信息熵
- 2、统计每个词的条件熵
- 3、两者相减就是每个词的信息增益