推荐系统的问题模式
我们知道,推荐系统的使命就是向用户推荐那些用户有可能交互的物品,所以推荐系统需要事先找出那些隐藏的物品呈现给用户,这是一个预测问题;而推荐系统从达成的连接目标角度区分,可以分为两大类:
评分预测
根据用户对物品的历史评分,建立模型预测用户对每一个物品的评分;然后将预测评分排名靠前,且用户没有交互的物品推荐给用户。具体的思想:建立一个模型,这个模型对用户历史评分过的物品预测分数,那么实际分数和预测分数之间会有误差,然后根据这个误差去调整模型参数,使这个误差越来越小,最后得到的模型理论上就可以为我们干活了。那么如何去衡量预测分数和实际分数的误差了?事实上,这是一个机器学习里面的回归问题,所以我们可以使用回归问题的评判标准,如RMSE(均方根误差):
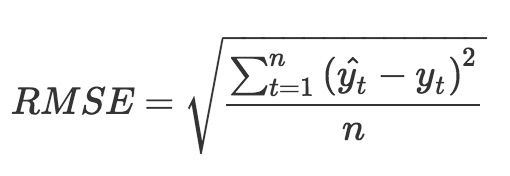
其中 t 表示每一个样本,即用户对物品的评分记录; n 表示样本总数;带帽的 yt 表示模型预测分数;没有带帽的 yt 表示实际分数;通过模型预测分数与实际分数相减,然后累加结果的平方和除以样本总数,再开根号,得到的结果就是我们预测的误差。
评分预测问题常见于各种点评类产品,如图书、电影、音乐的点评,但评分预测存在以下问题:
- 数据不易收集,用户对物品的评分行为说明用户已经完成了对物品的消费,而这部分用户相对于没有消费的用户,还是太少;
- 数据质量不能保证,伪造评分数据门槛低,同时真实的评分数据又处在整个消费转化过程的最后一环;
- 评分的分布不稳定,整体评分在不同时期会差别很大,个人评分在不同时期标准不同,人和人之间的标准差别很大。
行为预测
用户对物品的评分有叫做显式反馈,意思是用户非常清晰地告诉我们,他们对物品的态度,而相对应的隐式反馈,通常就是各类用户行为如点击、收藏等,根据这些行为建立的推荐系统就是行为预测。
- 行为预测的方式
- 直接预测行为本身发生的概率,又叫做 CTR预估 ; CTR 意思是 Click Through Rate ,即点击率预估。就是把每一个推荐给用户的物品按照“是否点击”二分类,构建分类模型,预测其中一种分类的概率。
- 预测物品的相对排序
- 行为预测相对于评分预测的特点
- 数据比显式反馈更加稠密,评分数据总体来说是很稀疏的;
- 隐式反馈更代表用户的真实想法;
- 隐式反馈常常和模型的目标函数关联更密切,也因此通常更容易在AB测试中和测试指标挂钩。比如 CTR预估 当然更关注点击这一隐式反馈。 使用评分预测的先决条件是用户必须先有评分行为,所以行为预测解决的是推荐系统 80% 的问题,评分预测解决的是最后20%的问题。
推荐系统的常见问题
冷启动问题:推荐系统属于数据贪婪型应用,所谓数据贪婪型应用,就是对数据的需求绝无满足的一天,冷启动问题广泛出现在互联网产品中,通常是新用户或不活跃用户,以及新物品或展示次数少的物品,这些用户和物品由于缺少相关数据,所以推荐系统很难对其进行推荐。通常的解决方式是想办法引入数据,如用户的年龄性别等,然后想办法从已有数据中主动学习。
探索与利用问题:又叫做EE问题,是Exploit(开采,)和Explore(探索)的缩写,意思是我们不仅要对用户身上已经探明的兴趣加以利用,同时还有探明用户身上还不知道的兴趣,也就是推荐物品中大部分包括用户喜欢的物品,同时还有小部分用于试探用户新的兴趣的物品。
安全问题:推荐系统攻击问题 1、给出不靠谱的推荐结果,影响用户体验并最终影响品牌形象; 2、收集不靠谱的脏数据,这个影响会一直持续留存在产品中,很难完全消除; 3、损失了产品的商业利益,这个是直接的经济损失。